周 楠,李福川+,宣 萱
(1.中国航天科工集团第二研究院 七〇六所,北京 100854;
2.中国航天科工集团第二研究院 重点型号部,北京 100854)
基于排队论的SRGM作为软件可靠性建模[1,2]研究中的重要分支,更准确地描述出由检测和修正两个子过程构成的测试工作[3]中故障所经历的历程,在可靠性的分析与评估方面展现出良好的能力。国内外研究者使用无限服务台排队(infinite server queuing,ISQ)模型建模软件测试过程,并逐步引入不完美排错和移动点等影响因素。但研究发现服务台数量是无限的假设,违背了真实的测试过程,通过修正ISQ模型的假设条件,考虑到时间延迟现象,提出有限服务台排队(finite server queuing,FSQ)模型。随着研究的深入,进一步挖掘队列平均长度、平均等待时间等排队论的核心内容,提出扩展的FSQ模型[4-8]。目前,队列模型主要对故障修正过程进行建模,忽略了软件从交付到检测过程中存在的排队等待现象。
针对上述问题,本文分析了资源相互独立的故障检测过程与故障修正过程,提出一种将排队论同时应用在检测与修正过程的双排队系统模型,并在建模中考虑不完美排错现象,实现对修正过程中可能破坏程序内部的逻辑结构,引入新故障现象的定量描述,从而提高模型对软件可靠性评估与预测的精度。通过对比实验验证模型的性能,同时对未来的发展趋势进行了展望。
当前的软件可靠性增长模型大多数都存在着与真实软件测试过程不相符合的假设条件[5,9,10],如完美调试、故障立即被修正以及测试工作量统一考虑等。而在实际的测试过程中,检测故障的工作通常由专业的软件评测人员来完成,开发人员则根据检测过程反馈的故障信息对程序代码进行修改,完成修正阶段的工作。两组不同的人员花费不同的CPU时间完成各自的任务,是资源相互独立的两个过程,因此需要将检测过程和修正过程消耗的工作量进行区分,建立各自过程的函数模型。

ωd(t)=ξω(t)
(1)
ωc(t)=(1-ξ)ω(t)
(2)
式中:ξ表示在t时刻的规模比率,在这里设置为常数。
测试资源作为一个综合性的影响因素,通常用执行的测试用例数目、消耗的CPU时间以及测试人员的数量等信息来度量。基于学习因素和软件结构的综合影响,在测试的初期,测试工作量通常会迅速增长,而随着过程的进行,增长速度会减缓,最后趋于平稳,呈现出一种S型变化趋势[11,12]。考虑到测试工作量这一变化特点,本文在建模过程中选用了变形S型TEF,如式(3)所示
(3)
式中:W表示最终消耗的总测试工作量;
α表示测试工作量消耗率;
A为一个常量。
将式(3)代入式(1)和式(2)后再对t进行积分,可以得到故障检测工作量函数以及故障修正工作量函数,如式(4)和式(5)所示

(4)

(5)
2.1 基本假设
(1)软件中失效事件随机发生,故障检测过程与修正过程服从非齐次泊松过程(non-homogeneous poisson process,NHPP)[9],设到t时刻累计检测出的故障数N(t)服从期望函数为m(t)的NHPP分布,满足t=0时, m(0)=0。
可以得到
(6)

(7)
式中:λ(τ) 表示τ时刻软件的失效强度函数。
在 (t,t+x] 时间间隔内不发生软件失效的概率,即软件可靠性为
R(x|t)=P{N(t+x)-N(t)=0}=e-m(t+x)+m(t)
(8)
(2)软件故障之间互不干扰且失效行为均是由未检测出的故障引发的[4]。
(3)在 (t,t+x] 时间区间内,累积检测到的故障数量与t时刻剩余未检测出的故障数量成正比,比例系数为故障检测率[4,9]。
(4)在 (t,t+x] 时间区间内,累积修正的故障数量与t时刻检测到但未被修正的故障数量成正比,比例系数为故障修正率[9]。
(5)引起软件失效的故障最终都会被修正,且故障检测过程在修正故障时会继续执行,故障的修正过程不会对故障的检测造成影响[4]。
(6) 使用两个不同的FSQ模型分别对故障检测活动以及故障修正活动进行描述,其中检测过程模型满足批量到达,修正过程模型满足NHPP到达。
(7)故障修正过程中,会引入新的故障且故障引入率为k[4]。
2.2 建模过程
2.2.1 故障检测过程
B(t)表示某个故障在(0,t]时间内被检测到的概率,包括两个部分:一部分是假设故障在0时刻到达,而且有空闲的检测人员对其进行检测,并在(0,t]时间内被检测到;
另一部分则是假设有限数量的检测服务人员都在工作中,故障在0时刻到达,并没有立即得到检测,而是在队列中等待一段时间(0,y]后,才在(y,t]时间内被检测到,如图1所示。

图1 在0时刻到达的故障在(0,t]内被检测到
根据乘法公式,B(t)表示为

(9)
式中:Ta表示故障被送达的时间点;
Tb表示检测故障时所用的时间;
Te表示故障等待检测时所用的时间。
软件交付到故障检测人员手中时也就意味着故障被送达,则令 P{Ta=0}=1, 代入式(9)可得

(10)
式中:D(t)表示不存在排队现象时服务人员检测故障所用时间的累积分布函数;
D(t-y) 表示存在排队现象时服务人员检测故障所用时间的累积分布函数;
L(y)表示故障在队列中等待检测时所用时间的累积分布函数。
在实际的故障检测过程中,需要考虑到软件设计的复杂度、故障检测人员的检测水平、检测工作量以及检测环境等因素对检测效果的影响。其中故障检测工作量随测试时间的变化情况对软件的可靠性增长曲线有显著影响,为了全面和准确地描述软件故障检测过程,在故障检测过程中引入故障检测工作量。另一方面,故障检测工作量对检测等待延迟也有一定的影响,随着投入的故障检测资源的增加,检测等待延迟会减小。因此,在分析检测等待延迟时,也需要考虑故障检测工作量。由于指数分布经常被假定为排队论中的服务时间分布[13,14],故假设故障检测时间的分布函数如式(11)所示
D(z)=1-e-ρdWd(t)+ρdWd(t-z)
(11)
故障检测等待时间的分布函数如式(12)所示
L(z)=1-e-μdWd(y)+μdWd(y-z)
(12)
式中:ρd表示每单位故障检测工作量的故障检测率;
μd表示每单位故障检测工作量的检测等待率。
根据式(11)和式(12)可得
D(t)=1-e-ρdWd(t)
(13)
D(t-y)=1-e-ρdWd(t)+ρdWd(y)
(14)
L(y)=1-e-μdWd(y)
(15)
将式(13)~式(15)代入式(10),可得
[1-e-ρdWd(t)+ρdWd(y)]dy
(16)
对式(16)求导得故障检测率函数,如式(17)所示

(17)
其中
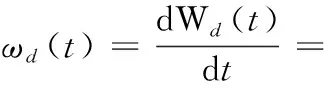
(18)
根据假设条件(7),考虑到故障修正过程存在引入新故障的现象,可以建立如下的微分方程
(19)
式中:a(t)表示随t发生变化的隐藏的故障总数,包括了初始故障数和引入故障数;
a表示初始故障总数。
代入初始条件md(0)=0, 可得如下故障检测过程模型
(20)
2.2.2 故障修正过程
P(t)表示某个被检测到的故障在 (0,t] 时间内被完全修正的概率,包括两个部分:一部分是假设故障通过检测过程在x时刻被发现,而且有空闲的修正人员对其进行修正,并在 (x,t] 时间内被完全修正;
另一部分则是假设有限数量的修正服务人员都在工作中,故障在x时刻被检测到,并没有立即得到修正,而是在队列中等待一段时间 (x,y] 后,才在 (y,t] 时间内被完全修正,如图2所示。

图2 在x时刻检测到的故障在(x,t]内被修正
根据乘法公式,P(t)表示为
(21)
式中:Td表示故障被检测到的时间点;
Tc表示修正故障时所用的时间;
Tq表示故障等待修正时所用的时间。
对式(21)做进一步变换,可得

(22)
式中:
G(t-x) 表示不存在排队现象时服务人员修正故障所用时间的累积分布函数;
G(t-y) 表示存在排队现象时服务人员修正故障所用时间的累积分布函数;
F(y-x) 表示故障在队列中等待修正时所用时间的累积分布函数。
在x时刻故障被检测到的概率为b(x),代入式(22)可得
(23)
实际的故障修正过程同检测过程一样会受到多种因素的影响,同样使用结合故障修正工作量的指数分布作为服务时间分布,故假设故障修正时间的分布函数如式(24)所示
G(z)=1-e-ρcWc(t)+ρcWc(t-z)
(24)
故障排错等待时间的分布函数如式(25)所示
F(z)=1-e-μcWc(y)+μcWc(y-z)
(25)
式中:ρc表示每单位故障修正工作量的故障修正率;
μc表示每单位故障修正工作量的排错等待率。
根据式(24)和式(25),可得
G(t-x)=1-e-ρcWc(t)+ρcWc(x)
(26)
G(t-y)=1-e-ρcWc(t)+ρcWc(y)
(27)
F(y-x)=1-e-μcWc(y)+μcWc(x)
(28)
将式(26)~式(28)代入式(23)可得
(29)
根据假设条件(4),可得
(30)
式中:mdt表示到t时刻为止,运用故障检测过程模型估计出的累积故障数量。
代入初始条件mc(0)=0, 可得如下故障修正过程模型
mc(t)=mdt[1-e-P(t)]
(31)
为了评估和验证模型的拟合效果以及预测能力,本节给出了4个具有代表性的模型评价标准,同时举例介绍了模型的参数估计方法,并根据已经公开发表的,在系统开发过程中所搜集到的4个软件失效数据集进行仿真实验,最后对模型的复杂度进行了分析。参与比较的所有模型见表1。

表1 参与比较的模型
3.1 模型的评价标准
模型拟合能力比较标准:
(1)均方误差
MSE是一个平均值,反映模型的输出值与累积故障数的真实值之间的偏差程度。MSE值越小,说明模型的拟合能力越好。
式中,n表示失效数据集中记录的样本条数;
m(ti)表示到时刻ti为止累积检测或修正的故障数的估计值;
mi表示到时刻ti为止累积检测或修正的故障数的真实值。
(2)Bias评价标准
Bias表示累积故障数的估计值和真实值之间的误差,反映模型本身的精确度。Bias值越小,说明模型的拟合能力越好。
(3)回归曲线方程的相关指数
R-square值距离1越近,说明模型的拟合能力越好。
模型预测能力比较标准:
(4)相对误差
一般会将RE值制成RE图,RE图中接近x轴的预测点越多,说明模型的预测能力越好。
3.2 失效数据集
失效数据集是对软件可靠性增长模型进行评估与预测的基础,多以日历时间作为故障检测与修正的时间周期。记录项依据软件公司对数据的需求以及收集方式的不同存在差异,包含的基础信息有累积检测的故障数量和消耗的CPU时间,部分含有累积修正的故障数量,更全面的会有故障类型等信息。失效数据的质量好坏会对实验结果准确与否产生巨大影响,实验中选用的4个失效数据集是已经公开发表,并在软件可靠性领域得到广泛应用的,因此可以保证数据的有效性和准确性。
DS1:RADC-T1数据集[18]
RADC-T1失效数据集是罗马空军开发中心发布的实时指令控制应用系统的失效数据,测试周期为21周,软件测试人员花费300.1CPU小时,共检测到并纠正了136个故障。
DS2:Okumoto数据集[19]
Okumoto失效数据集是K.Okumoto发布的Alcate/Lucent公司的失效数据,测试周期为56周,软件测试人员花费6423.5CPU小时,共检测出124个故障。
DS3:Ohba数据集[19]
Ohba失效数据集是Ohba发布的PL/1项目的失效数据,测试周期为19周,软件测试人员花费47.65CPU小时,共检测出328个故障。
DS4:Wood数据集[12]
Wood失效数据集是Alan Wood在1996年发表的一篇论文中收集的某个项目的失效数据,测试周期为20周,软件测试人员花费10000CPU小时,共检测出100个故障。
3.3 模型参数的拟合方法
由于失效数据集通常数据量较小,因此本文采用最小二乘法拟合模型参数,以故障检测过程模型为例:设数据集中一共采集到n组故障数据信息,在时间区间(0,ti)内,实际检测出的累积故障数量为mi,模型预估出的累积故障数量的均值函数为md(ti), 其中i=1,2,…,n; 在实测数据mi和均值函数md(ti) 均已知的情况下,用它们之间的残差和来估计模型参数,表示为< p> 接下来只需对SSR中未知的参数逐个求偏导,并令求导后的结果等于0,即可求出使得SSR达到极小化的参数估计值。本文采用分步方法,首先基于测试工作量数据,拟合出Wd(t)中的参数估计值,见表2,然后将估计出的参数值代入模型中对md(t)中剩余的参数进行计算,估计结果见表3。 表2 测试工作量函数的参数估计值 表3 参与比较的模型的参数估计值 3.4.1 故障检测过程 检测过程的拟合曲线如图3所示,从中可以观察到,在DS1和DS2上,G-O模型的拟合曲线严重偏离实测数据的失效曲线,主要原因在于G-O模型的建立没有充分考虑真实情况,假设条件过于简化; 图3 各个模型的累积检测的故障数量拟合曲线 为进一步比较不同模型的性能差异,下面定量化地计算出各个模型在3个判定标准上的数值,具体数据见表4,其中带有双下划线标注的表示最优标准值,带有下划线的表示次优标准值,最差标准值采用波浪线表示。 表4 模型的拟合性能度量比较 从表4可以看出,在DS1上,新建模型表现最优,在3个比较标准中,2个最优,1个次优,且与最优的标准值仅相差在小数点后第三位上; (1)新建模型在建模过程中考虑到FDR的复杂性,与TEF相结合构建出复合型FDR,实现了对故障检测过程更为真实的描述; (2)考虑到引入测试工作量因素,且选取了变形S型TEF,更准确地反映了测试过程中测试工作量的变化情况; (3)应用不完美排错对故障修正过程引入新故障的现象进行建模,充分体现程序结构的关联性以及环境和人员的随机性; (4)排队论的引入进一步挖掘了故障所经过的活动历程,基于队列的研究,时间延迟这一必不可少的环节得以进行模型化表示。 另一方面,检测过程的预测曲线如图4所示,从中可以观察到,G-O模型在DS1上预测效果很不理想,但在另外3个数据集上呈现出的效果明显好于DS1,说明模型适用性差,具有极强的不稳定性; 图4 各个模型的预测RE曲线 3.4.2 故障修正过程 失效数据集根据采集到的故障属性列一般可分为两种类型[12]:一种是只包含累积检测的故障数量属性,目前这种数据集在数量上占据着很大的优势,但对于其应用的局限性正在逐渐显露出来; 表5 提出模型的参数估计值 修正过程的拟合曲线如图5所示,从中可以看出,新建模型在故障修正过程中与真实数据的失效曲线贴合紧密,展现出较好的拟合能力,进一步,通过表6中的拟合标准,可以更直观地判断模型的性能。与故障检测过程相比,模型的拟合标准值有一定的下降,但下降的幅度并没有超过标准自身的量级,仍然展现出比较好的拟合效果。原因在于故障修正过程的建模是以故障检测过程为基础,会使用检测过程中估计出的参数值,这些参数值本身与实际情况存在误差,代入修正过程后导致最终结果的误差进一步扩大。 图5 提出模型在DS1上的拟合曲线 表6 提出模型的拟合性能度量 另一方面,修正过程的预测曲线如图6所示,从中可以看出,模型故障修正过程的预测曲线与检测过程呈现相同的变化趋势,后期预测性能明显优于前期,虽然没有故障检测过程的预测能力表现优异,但RE值的最大变化范围没有超过1,还是展现出比较好的预测能力。 图6 提出模型在DS1上的预测曲线 3.4.3 模型复杂度分析 新建模型由于结构复杂以及参数量增多导致模型的复杂度有显著提高,通过统计相同硬件条件下各个模型执行1000次所用的平均CPU运行时间以及参数和变量占用的内存空间,对模型的计算性能进行分析。具体数据见表7。 表7 模型的计算性能度量比较 由表7可知新建模型的CPU运行时间相比于其它模型有数倍到数十倍的增加,在数据规模较大的DS2上表现尤为明显,随着输入数据量的增大,模型的运行时间差距会进一步扩大。但由于失效数据集的规模通常较小,模型的CPU运行时间保持在零点几秒到几秒之间,相比于模型拟合和预测精度的提升,所付出的时间代价是可接受的。同时各个模型中参数和变量占用的内存空间在几十KB范围,所有模型处于同一个数量级,且差异很小,不会对当前的计算机硬件环境形成挑战。因此,新建模型虽然复杂度有显著提升,但在解决软件可靠性评估和预测的问题上是可行的,并且结果是更精确的。 本文建立的基于双排队系统的SRGM,考虑到故障检测过程和故障修正过程中存在的时间延迟现象,并基于测试工作量函数对故障检测率进行重构,实现了对真实测试过程更为符合现实的描述。通过对比实验验证在选定的失效数据集上与若干经典SRGM相比,其展现出更好的预测效果和拟合能力。新建立的模型存在的问题便是引入了更多的参数,导致模型的复杂度上升和可理解性下降。未来,通过对排队论技术的进一步研究,向着模型复杂度更低,性能更优的方向发展。
0

3.4 模型性能的比较分析
Huang模型和Yamada模型在建模过程中本质相同,但可以明显看到Huang模型在测试周期开始时拟合效果不佳,几个周期过后表现得较好,两个模型表现出的性能各异,原因在于模型之间采用的TEF存在很大的差异。新建模型在所有4个失效数据集上,性能表现稳定,与真实失效曲线拟合程度较高,体现出良好的拟合能力。

P-N-Z模型次之,1个最优,2个次优;
G-O模型表现最差,3个标准均是最差。在DS2上,新建模型表现最优,在3个比较标准中均是最优;
P-N-Z和Pham模型次之,3个均是次优;
G-O模型表现最差,3个标准均是最差。在DS3上,新建模型表现最优,在3个比较标准中均是最优;
P-N-Z模型和Pham模型性能表现相同,优于剩下的模型,3个标准值均是次优;
Huang模型表现不理想,MSE和S-square标准均是最差,而Bias接近最差。在DS4上,新建模型表现依旧稳定,在3个比较标准中,1个最优,2个次优,且与最优的标准值相差不大;
Huang模型次之,1个最优,1个次优;
Yamada模型表现不理想,MSE和R-square标准均是最差,而Bias接近最差。新建模型性能表现良好,可能基于以下原因:
Huang模型的RE值在DS2、DS3和DS4上第一周期偏离0异常明显,但是从第二周期开始迅速趋近于0,并且预测效果越来越好;
新建模型在4个数据集上的预测效果表现优异,波动范围较小,可以清晰地看到优于其它模型;
所有模型的RE图有一个共同特点,后期预测性能均优于前期,尤其是在12周之后。这是因为利用SRGM进行可靠性预测,首先需要充足的数据作为支撑;
同时由于模型中的参数数量不一,需要数据规模超过参数数目一定的比例,才能达到更好的预测性能。
另一种是除累积检测到的故障数量外同时包含累积修正的故障数量属性,全面的故障属性列更符合当前的研究趋势。DS1属于第二种数据类型,而DS2、DS3以及DS4均属于第一种,故接下来只使用DS1对故障修正过程的模型进行验证。前5个经典模型在建模过程中并没有将故障检测过程与故障修正过程作为两个不同的阶段进行考虑,因此5个经典模型无法对DS1中故障修正过程进行建模。本文只对新建模型的故障修正阶段性能进行分析,并与模型的检测阶段性能进行纵向对比,其中修正阶段模型的参数估计值见表5。



