任家豪,张光华,乔钢柱,武秀萍
(1.中北大学 大数据学院,太原 030051;
2.太原学院 智能与自动化系,太原 030032;
3.山西医科大学 口腔医学院,太原 030001)
在临床诊断、治疗与手术决策中,头影标志点通常由经验丰富的医生手动或半手动标记,耗时且出错率较高。因此,目前市场上对自动且高精度的标志点定位模型有较大的需求。但是,由于个体头影结构的差异以及X 线图像的模糊性与复杂性,自动检测标志点的难度较大。
目前,已有很多研究人员提出优秀的自动解剖标志点检测方法。GRAU 等[1]使用模板匹配的规则定位标志点,但随着图像复杂度的增加,规则不再具有权威性与实用性。为了同时考虑标志点的局部形状与全局空间结构,KEUSTERMANS[2]等使用基于局部外观的模型进行自动检测标志点,而IBRAGIMOV[3]等则采用博弈策略和基于形状的模型提取X 射线图像特征。上述方法需要复杂的人为设计,且性能有待提高。文献[4-6]将支持向量机、随机森林等机器学习方法应用到标志点定位中,同时利用图像片段的局部信息与器官的大小、姿态等全局信息训练模型,较好地提高了预测精度。
近年来,深度学习在图像分类[7]、分割[8]、目标检测[9]等领域取得了巨大的成功,并广泛应用于需要进行解剖标志点检测的医学图像分析中。LEE 等[10]将深度卷积神经网络(Deep Convolutional Neural Network,DCNN)应用于头影标志点检测,通过训练38 个独立的卷积神经网络(Convolutional Neural Network,CNN),分别回归了19个标志点的x与y坐标,这种方法极大地增加了训练时间。针对医学训练图像有限的问题,AUBERT等[11]以局部小块图像为样本进行坐标点回归,但这种基于图像块的方法只能利用局部信息而忽略全局信息,无法对所有标志点进行准确预测。ARIK 等[12]使用CNN 对输入图像的小块进行训练,输出标志点的概率估计,并通过基于形状的模型对标志点的位置进行细化。由于上述方法都是基于标志点坐标的直接回归,丢失了特征图上的空间信息,因此学者们提出了基于高斯热图的方法来回归坐标点,如PAYER等[13]将U-Net网络与空间配置网络相结合,ZHONG等[14]使用全局U-Net将整张图像输入,而局部U-Net将19个图像块作为输入,实现了低分辨率与高分辨率相结合的热图回归。
由于图像训练数据集有限,现有多数医学影像标志点检测算法均采用非常浅显的网络进行特征提取,并没有以高分辨率输出特征图,导致预测值与真实值产生量化误差。多尺度特征融合的方法通过将高层语义信息与低层语义信息相结合,使关键点定位任务中输入的多尺度特征信息更加丰富,从而提高检测精度,很好地解决上述问题。受此启发,QI等[15]提出一种人脸关键点检测网络,引入多尺度特征图融合思想来提升主干网络MobileNet 在人脸关键点检测的准确率。ZHANG[16]和LI[17]分别利用主干网络 MobileNetV3 和沙漏网络(Hourglass Network,HN)实现多尺度特征的提取和融合,同时在特征融合时通过添加注意力机制对不同尺度标志点信息进行集中学习,最后精确地输出交通标志中心点(MRI 解剖点)的位置信息。
为了将多尺度特征融合的思想应用到医学标志点检测中,本文提出一种改进的多尺度特征融合检测模型AIW-Net,其中W-Net 相比只有两条采样路径的U-Net[18]、V-Net[19]的特征融合更加多样化。AIW-Net使用基于Imagenet 数据集进行初始化的预训练模型MobileNetV2 进行特征提取,中间模块受Bi-FPN[20]的影响采用双向采样路径,在下采样过程中采用改进的倒残差结构减少特征损失。解码器采用上采样卷积路径,使特征图的尺寸恢复到原始分辨率大小,同时将得到的多个尺度的热图与特征图相结合。
AIW-Net 使用轻量级网络MobileNetV2 作为骨干网络。针对图像的不同分辨率,MobileNetV2 的特征提取部分可以被灵活划分为几个不同的阶段。MobileNetV2 相比VGG、ResNet 等其他骨干网络,在保持相同预测精度的同时显著减少了所需操作与内存数量。MobileNetV2 的核心模块为倒残差(Inverted Residuals)模块,与传统残差模块的卷积结构相反,该模块的结构为“扩展-深度分离卷积-压缩”。本文将MobileNetV2 网络划分为5 个阶段,在每个阶段对输出的特征图采用步长为2 的卷积,特征图的分辨率均减小1/2。在每个阶段之后将其输出的通道数目进行调整,使用MobileNetV2_c 表示调整后的网络,其结构如图1 所示。其中:t表示通道膨胀系数;
c1 与c2 分别表示原始输出与调整后的通道数;
n表示重复模块个数;
s表示步长;
“—”表示该数据未知。
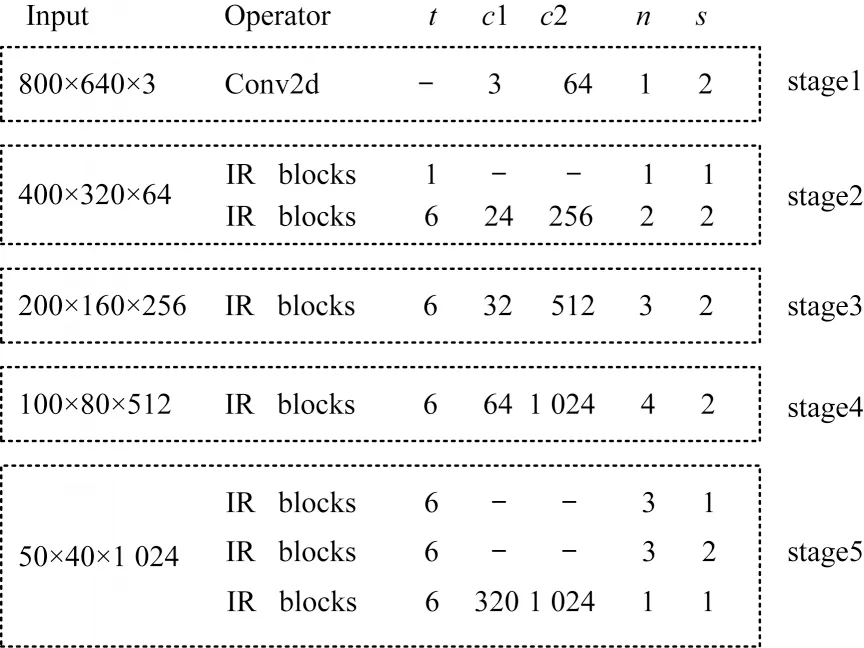
图1 MobileNetV2_c 网络结构Fig.1 Structure of MobileNetV2_c network
本文的主要任务是从头颅影像中找出所有标志点{P1,P2,…,P19}的位置。图2 所示为AIW-Net 的网络结构,其中每个特征图上方的数字为通道数量。由图2 可知,该网络由提取特征的轻量级编码器网络MobileNetV2_c、对多尺度特征进行融合的中间模块、对多尺度预测热图进行不断优化更新的解码器网络组成。为方便叙述,定义特征尺度水平{W0,W1,…,Wn},分别对应具有0,2,…,2n像素的输入图像步长。在以往的多尺度特征融合研究中,FPN[21]与PANet[22]网络通过特征图相加的方式仅融合了ResNet 骨干从W2到W5的尺度水平。而Bi-FPN[20]仅结合了EfficientNet 网络从W3到W7的尺度水平。相较而言,本文的中间模块与解码器网络结合了MobileNetV2 网络从W0到W5的所有尺度水平(包括与输入图像具有相同分辨率的尺度水平W0),整个网络能够使用更高分辨率的特征。

图2 AIW-Net 网络结构Fig.2 Structure of AIW-Net network
2.1 中间模块设计
本文定义fj(j=0,1,2)为中间模块与解码器网络的第j条采样路径的特征图。中间模块部分包括一个双向(上采样与下采样)路径,如图3 所示。在上采样路径中,每张特征图以2 的倍数进行上采样,该路径的基本单元如图3(a)所示。图3(b)所示为中间模块下采样路径的基本单元。骨干网络中输出的第i层(i=1,2,3,4,5)特征图为Fi,它与第i+1 层上采样操作Up后的特征图执行通道合并的融合操作⊕后,采用ReLU激活函数,最终得到输出,其表达式如式(1)所示:

图3 中间模块路径的基本单元Fig.3 Path basic unit of intermediate module
骨干网络最终生成的尺度特征图F5经过3×3和1×1的卷积层后,构成了上采样路径中的第1 个开始单元。
在下采样路径中,为了弥补图像分辨率逐渐降低造成的信息损失,采用一种改进的倒残差网络结构(stride=2)进行下采样,通过深度可分离卷积大幅减小网络模型的参数个数,该网络结构将在2.2 节详细介绍。下采样之后的特征图与上采样路径中具有相同分辨率的特征图进行连接,得到新的特征输出,其表达式如式(2)所示:
其中:IR*为自定义的倒残差卷积操作。
2.2 改进的倒残差结构
为尽量避免由于下采样过程中出现图像特征损失导致的标志点预测准确率下降问题,采用MobileNet 系列中一种称为“倒残差”的结构,即每次经过深度卷积过滤之后与该次深度卷积之前的图像特征进行相加,并作为下一次的输入。该结构包含轻量级卷积,即深度可分离卷积,其相对于普通卷积最大化地减少了网络的参数量。原始的倒残差结构在输入尺寸与深度卷积后的尺寸不同的情况下(stride=2)直接采用卷积后的特征作为下一模块的输入。受步长为1 的倒残差结构[23]的启发,本文将该结构进行改进,即将输入图像的分辨率大小经过3×3 的深度卷积变换生成与输出尺寸相同的特征图,并将两者合并作为下一次卷积的输入。为尽量避免模型发生过拟合现象,采用ReLU6 激活函数加速模型收敛,该函数的计算式如式(3)所示。
改进前后步长为2 的倒残差结构如图4 所示。显然,将改进后的结构应用于下采样过程后,特征图中不仅包含了通过卷积操作后分辨率减半的特征,而且增加了对输入图像进行深度卷积后的特征,从而使下采样输出的特征图信息更加丰富。
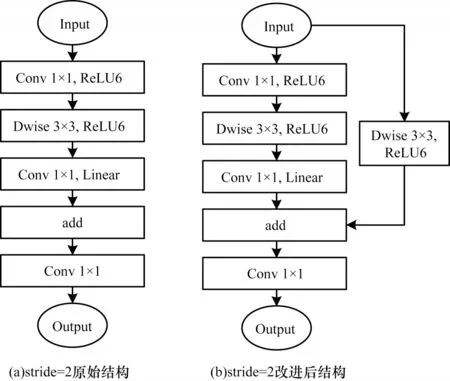
图4 改进前后的倒残差结构Fig.4 Backward residual structure before and after improvement
2.3 解码器设计
与U-Net 网络中的解码器设计类似,本文解码器部分也是一条上采样路径,每次以2 的步长上采样,最终使特征分辨率从W5恢复到W0,如图4 所示。由于在低级特征层上图像分辨率逐渐变大,因此使用小的通道来减小参数数目。在W2与W1特征层将合并后的特征图通道数分别减少为256、128。同时为了在最高分辨率的特征图上得到最优关键点信息,引入从粗到细的中间监督进一步细化标志点的定位。定义第i个尺度(i∈{0,1,2,3})的特征融合映射关系φi:Pi=φi(a,b),表示将特征图a进行上采样后与特征图b进行通道融合⊕操作;
gi,i∈{0,1,2}表示在每个尺度上对融合的特征图经过3×3 与1×1 的卷积操作,生成不同分辨率预测热图的映射函数,每个尺度上的映射关系如式(4)~式(6)所示:
其中:UP为上采样操作;
Pi表示在第i个尺度上生成的中间特征图;
yi表示在第i个尺度上Pi经过1×1卷积最终生成的特征图;
hi∈R2表示预测的二维关键点热图,每个通道代表一个关键点的热图。每个尺度生成的预测热图数量关系如式(7)所示:
由式(7)可知,最终生成的特征图y1与预测热图h1进行特征融合后,能得到与输入图像F0具有相同分辨率的热图h0,达到最高分辨率的热图回归。该方法可以更加精确与细化地预测头影图像标志点。
2.4 注意力门模块
在解码器模块与中间模块的下采样路径之间引入针对通道的门信号思想,将下采样路径与解码器节点的跳跃连接替换为注意力门模块,使最终输出的特征图注意力集中在标志点附近区域,有效抑制特征图中对标志点定位产生负面影响的背景区域响应。注意力门模块由多个函数构成,定义如下:
其中:xi∈RH×W×Ci(i=1,2,3,4)为特征尺度Wi所对应的下采样过程中经过1×1 卷积的输出矩阵,H,W为特征图的分辨率大小,Ci为输出特征图的通道数;
gi∈RH×W×C1为解码器上采样之后的输出矩阵;
σ1与σ2分别为ReLU 与Sigmoid 激活函数;
ψT∈R1×1×1、均是线性变换为1×1 卷积的参数矩阵;
bg∈RC与bψ∈R 为卷积的偏置矩阵;
输出的注意力系数为连接操作之前注意力门的输出结果;
⊗为矩阵点乘操作。注意力门模块如图5所示。

图5 注意力门模块Fig.5 Attention gate module
2.5 热图回归与损失函数
对于热图回归,标志点检测的实质是预测以每个真实标志点为中心的非标准化高斯分布的热图,然后执行非极大抑制恢复标志点的坐标。为提高标志点的回归精度,将更加关注标志点附近像素处的误差,更少关注背景区域的像素误差。基于此,本文提出一种改进的MSE 损失函数,其表达式如式(10)所示:
其中:y与分别表示真实热图与预测热图每个位置的像素值;
λ为超参数,可以对真实热图的像素真值进行指数加权,随着与标志点距离的增加,权值λy逐渐减小为1。在训练过程中,解码器在多个尺度Wi上多次生成标志点热图hi,在每个热图输出处定义一个像素平均损失函数Li,最终得到AIW-Net 的损失函数L,如式(11)~式(12)所示:
3.1 数据集与评价指标
3.1.1 数据集及其处理
本文采用ISBI 2015 Grand Challenge[10]提供的 cephalometric X-rays 数据集进行头影标志点检测,共400 张cephalometric X-rays 图像,每张图像均包含由2 名专业医生标注的19 个标志点,图像示例见图6。表1 列出了图6 标注的19 个标志点及其名称。取2 名医生标注的平均值作为训练与测试的真实标签。每张图像的分辨率为2 400×1 935 像素,每个像素值大约为0.1 mm。cephalometric X-rays 数据集划分为用于训练的150 张图像以及用于测试的150 张Test 1 数据集与100 张Test 2 数据集。为加速网络收敛,对每一张图像进行归一化的增强操作,将输入X-rays 图像RGB 通道的均值分别设置为mean=[0.485,0.456,0.406],对应的方差分别是std=[0.229,0.224,0.225]。
图6 cephalometric X-rays 图像示例Fig.6 Example of cephalometric X-rays image

表1 19 个标志点及其名称Table 1 19 mark points and their names
3.1.2 评价指标
受ISBI 2015 Grand Challenge 的启发,本文将平均径向误差(Mean Radial Error,MRE)与成功检测率(Successful Detection Rate,SDR)作为头影标志点检测的评价指标。平均径向误差表达式如式(13)和式(14)所示:
其中:Δx与Δy分别为预测标志点与真实标志点在x与y坐标上的绝对误差;
K为标志点的数量;
N为测试阶段图片的数量。成功检测率表示若绝对误差在某个范围内,则认为它在该范围内是正确的,成功检测率的表达式如式(15)和式(16)所示:
其中:z代表测量范围;
N0表示在该范围内的图片数量;
N为测试时全部图片的数量;
K为标志点的数量。在实验中,SDR 评估了当z=2.0 mm,2.5 mm,3.0 mm,4.0 mm时模型成功检测到标志点的百分比。
3.2 实验环境与参数设置
实验基于PyTorch1.8.0 框架与Python3.6 实现,将输入网络的图像设置为800×640 像素大小。经过多次训练比较,设置损失函数的超参数λ为50,初始学习率为0.000 1,每经过50 个epoch 便以0.1 倍进行衰减。使用Adam 优化器对网络在GeForce RTX 2080 Ti GPU 上进行500 个epoch 的训练,每次批量大小设置为1。
3.3 对比实验
3.3.1 与其他头影标志点检测模型比较
将现有头影测量标志点检测模型与本文AIWNet 模型的性能进行对比,结果如表2 所示,表中加粗数字表示该组数据最大值,“—”表示无此数据。由 表2 可 知,AIW-Net 模型在Test 1 与Test 2 数据集上的MRE 分别为1.14 mm 与1.40 mm,与文献[14]提出的模型性能相当,但相较于文献[3]、文献[6]与文献[12]所提出的模型性能有大幅提升。当z=2.0 mm,2.5 mm,3.0 mm,4.0 mm 时,AIW-Net 模型的SDR 值在Test 1 数据集上分别为86.38%、92.10%、95.50%与98.52%,在Test 2 数据集上分别为75.91%、83.52%、89.31%与94.68%。
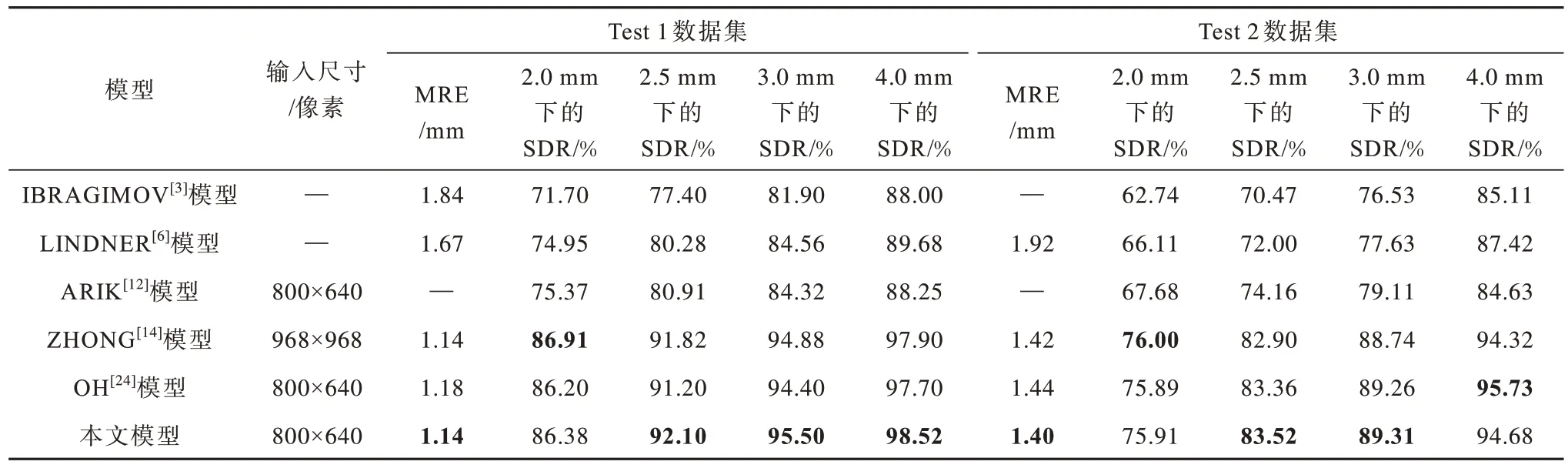
表2 AIW-Net 模型与其他模型的检测结果Table 2 Detection results of AIW-Net model and other models
IBRAGIMOV 等[3]和LINDNER 等[6]模型通过结合随机森林与统计形状机器学习模型取得了不错成绩,与以上模型相比,AIW-Net 模型的SDR 值在Test1 数据集2 mm 检测范围内分别增加了14.68%、11.43%,MRE 值分别减少了0.70 mm 和0.53 mm。在基于深度学习的模型中,相对于最先进的ZHONG[14]模型,本文模型在2.5 mm、3 mm 以及4 mm 检测范围内的成功检测率均高于该模型,虽然本文模型在2 mm 范围内的SDR 值低于ZHONG[14]模 型,但ZHONG[14]模型采用多个阶段U-Net 网络(全局与局部U-Net)以及基于图像块的模型回归热图,增加了时间与运算成本。
将本文模型分别与OH[24]模型、ZHONG[14]模型进行对比,采用模型参数量、运算复杂度、模型尺寸、单张图像训练时间4 个指标进行评价,结果如表3所示。

表3 不同模型复杂度的对比结果Table 3 Comparison results of complexity of different models
由表3 可以看出,本文模型通过使用轻量级主干网络MobileNetV2,并在采样路径中采用改进的倒残差结构而没有使用普通卷积层,加快了模型收敛,使模型参数量比ZHONG[14]模型降低了28M;
在运算复杂度与模型大小上,本文模型比ZHONG[14]模型降低了16.8 frame/s 和162 MB,能够部署到资源受限的设备上。在batch size 同为1 的情况下,本文模型的单张图像训练速度相对于ZHONG[14]模型提高了将近1.5 倍。OH[24]模型在复杂度指标上与本文模型基本相当,但在Test 1 与Test 2 数据集上的MRE 值与SDR 值却不及本文模型。综上可知,本文模型在模型运算复杂度与预测精度之间实现了平衡。
3.3.2 与经典关键点检测模型的对比
为进一步说明本文AIW-Net 模型的有效性,对比了其他先进的关键点检测模型在Test 1 数据集上的结果,结果如表4 所示,表中加粗数字表示该粗数据最大值。
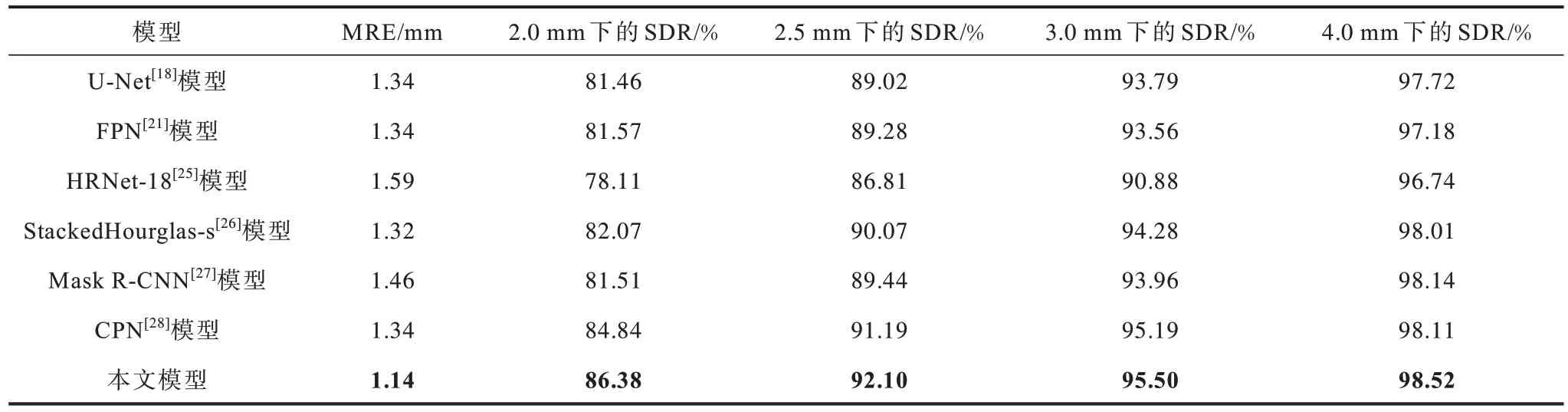
表4 不同模型在Test 1 数据集上的结果对比Table 4 Comparison of results of different models on Test 1 dataset
由表4 可知,本文模型相对于其他关键点检测模型性能较好,而且在临床实践可接受的2 mm 与2.5 mm 范围内,其SDR 值相对于性能次之的CPN 模型分别提高了1.54%、0.91%。Unet 模型使用较浅的骨干网络VGG 作为编码器,在网络训练过程中需要900 个epoch 才能达到最终收敛。AIW-Net 模型相对于FPN 模型而言,其MRE 值直接减少了0.20 mm,表明使用增加双重采样路径和采用通道合并的融合方式可以实现更好的特征融合。表4 中其余几种模型在二维人体姿态估计[22-24]任务中表现出了良好的性能,但在静态的医学图像关键点检测中却表现一般。AIW-Net 模型将人体姿态估计的热图回归方法引入到医学图像中,在图像关键点的回归与自动定位中实现了重大突破。
3.4 消融实验
为验证本文所提标志点检测模型的合理性与优越性,在Test 1 数据集上进行了消融实验。针对本文所设计的引入中间监督的多尺度热图融合结构、改进的倒残差结构、注意力门模块,与以下模型进行对比:
1)W-Net*模型,其经过预训练且未添加上述模块,损失函数为多尺度指数加权(multi-EW)函数,该模型的形状类似于“W”。
2)W-Net 模型,添加多尺度中间热图的结构。
3)IW-Net 模 型,在W-Net 模型中添加改进的倒残差结构。
4)AIW-Net 模型,在IW-Net 模型中添加注意力门模块。
5)AIW-Net*模型,使用多尺度均方差(multi-MSE)作为损失函数。
不同模型在Test 1 数据集上的实验结果如表5所示,表中加粗数字为该组数据的最大值。

表5 不同模型在Test 1 数据集上的结果Table 5 Results of different models on Test 1 dataset
由表5 可知,AIW-Net 模型的表现性能最好,在临床可接受范围2 mm 与2.5 mm 内的SDR 值分别为86.38%与92.10%。通过对比W-Net*与W-Net 模型可知,使用中间监督生成不同尺度的热图,然后将不同尺度的热图与特征图进行融合,能够使MRE 值降低0.08 mm,使得在2 mm 范围内的SDR 值提升了0.68%,这说明热图融合的方法在特征提取方面发挥了良好的作用。
由表5 还可知,由于W-Net 模型在原模型的基础上添加了倒残差结构(IR*),使得其标志点的MRE值直接从原来的1.28 mm 降低为1.18 mm,且在2 mm、2.5 mm 以及3 mm 范围内的SDR 值均有所提升。由于标志点的像素区域比背景区域小得多,容易影响标志点的准确预测,因此本文通过添加注意力门模块使特征图的响应集中在目标关键点周围,降低受其他背景结构(如耳朵,牙齿,下颌骨)遮挡的标志点的错误检测率,具体结果如图7 所示。由图7可知,由于AIW-Net 模型添加了注意力门模块,图7中第1 行被耳朵与牙齿遮挡的标志点4 与标志点6,以及图7 中第2 行被下颌骨背景遮挡的标志点10,其定位效果都更加接近真实标志点。

图7 添加注意力门前后标志点检测结果Fig.7 Detection results of mark points before and after adding attention gate
图8 与 图9 分别为AIW-Net 模型在Test 1 与Test 2 数据集上输出图像与输入图像具有相同分辨率(800×640 像素)的预测热图,以及由热图转换的预测点与真实点可视化结果。从图8 与图9 可知,即使在个体头部组织结构存在较大差异以及在采集的X 射线图像较模糊的情况下,本文模型依然能准确预测标志点。最后本文对比了不同损失函数对AIW-Net 与AIW-Net*模型性能的影响,具体结果如表5 最后两行数据所示,可以看出,使用多尺度指数加权(multi-EW)函数后,MRE 值减少了0.03 mm,且在标志点附近2 mm 误差范围内的SDR 值达到了86.38%,证明了本文所提损失函数的有效性。

图8 AIW-Net 模型在Test 1 数据集上的可视化结果Fig.8 Visualization results of AIW-Net model on Test 1 dateset
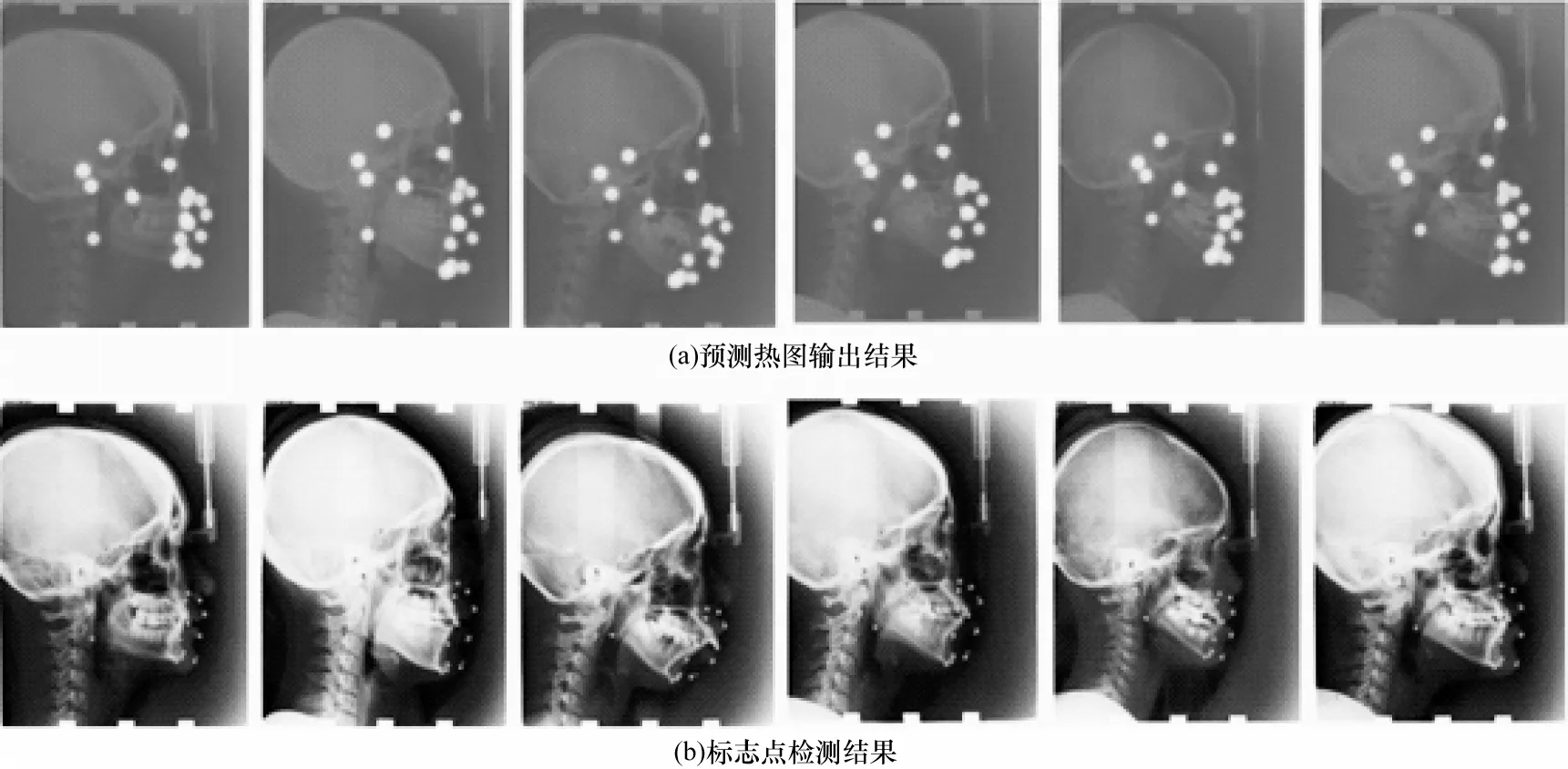
图9 AIW-Net 模型在Test 2 数据集上的可视化结果Fig.9 Visualization results of AIW-Net model on Test 2 dateset
本文面向头影测量X 射线标志点检测任务,提出一种改进的多尺度特征融合的AIW-Net 端到端检测模型。采用预训练的轻量型网络MobileNetV2 提取特征,并通过中间模块与解码器不断优化检测效果。在中间模块的下采样路径中采用改进的倒残差结构减少特征损失,在解码器中采用上采样卷积路径将特征图尺寸恢复到到原始分辨率大小,并引入从粗到细的中间监督思想,实现多个尺度热图与特征图的融合。实验结果表明,本文模型在临床实践可接受误差范围内的检测效果好于W-Net、IW-Net等模型。下一步将对解码器网络以及数据增强方式进行改进,解决头影标志点检测模型在头影边缘轮廓区域的检测精度相对其他区域较低的问题。
猜你喜欢热图标志点尺度财产的五大尺度和五重应对内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06标志点定向系统几何精度因子的计算方法测控技术(2018年12期)2018-11-25一种圆形编码标志点的设计及解码算法研究传感器与微系统(2018年7期)2018-08-29热图摄影之友(2016年12期)2017-02-27宇宙的尺度太空探索(2016年5期)2016-07-12每月热图摄影之友(2016年8期)2016-05-14基于标志点的三维点云自动拼接技术计算机工程与设计(2014年9期)2014-12-239时代英语·高三(2014年5期)2014-08-26Mean Shift的渐进无偏变换图像配准电子与信息学报(2012年2期)2012-04-29室外雕塑的尺度雕塑(2000年2期)2000-06-22